
Created by. 솔루션사업팀
<aside> 💡 CLIP
OpenAI에서 발표한 모델이다. 기존 ImageNet 보다 방대한(약 4억개) 용량의 이미지 데이터를 사용하여 representational learning을 수행하였다. 기존의 이미지 사전 학습에서는 영상 분류 문제인 ImageNet 데이터셋을 주로 사용하였다. 주어진 이미지를 보고 그 이미지가 보여주는 물체(object)의 종류를 알아 맞추는 것이다. 이러한 영상 분류 문제에는 두 가지 한계점이 있다.
첫 번째 문제는 물체에 대한 labeling이 필요하다는 것이다. 비교적 간단한 label이기는 하지만 이미지 수가 백만, 천만개가 넘는 대용량 데이터셋을 구축할 경우 물체의 분류를 정의하고 labeling 하는 것이 엄청난 부담이 된다.
두 번째 문제는 label이 지니는 정보의 양이 너무 적다는 것이다. 이미지에 포함된 다양한 정보들 중 물체의 ‘종류’라는 단일 정보만을 표현하기 때문에 이미지가 가진 다양한 특징을 활용하는데에는 한계가 있는 것이다.
CLIP 에서는 (이미지, 물체 분류) 데이터 대신 (이미지, 텍스트) 데이터를 사용하는데, 수작업 labeling 없이 웹 크롤링을 통해 자동으로 이미지와 그에 연관된 자연어 텍스트를 추출하여 4억개의 (이미지-텍스트) 쌍을 가진 거대 데이터셋을 구축하였다.
</aside>
<aside> ⚠️ CLIP 모델 구조 및 학습 방법
(이미지, 텍스트)로 구성된 데이터셋은 정해진 class label이 없기 때문에 분류(classification) 문제로 학습할 수는 없다. 따라서 CLIP 논문에서는 주어진 N개의 이미지들과 N개의 텍스트들 사이의 올바른 연결 관계를 찾는 문제로 네트워크를 학습하였다.
위의 그림에서와 같이 이미지 인코더, 텍스트 인코더가 있으며, 각 인코더를 통과해서 나온 N개의 이미지, 텍스트 특징 벡터들 사이의 올바른 연결 관계를 학습한다. 이미지, 텍스트 인코더 모두 Transformer 기반의 네트워크를 사용하였다. 데이터셋의 크기가 큰 만큼 학습에 많은 시간이 소요된다. (256개의 V100 GPU 를 이용해서 12일간 학습)
이 논문에서는 매우 다양한 실험을 통해 이렇게 학습된 모델의 유용성을 보여주고 있다. 첫번째로 zero-shot learning 가능성을 테스트하였다. 이 논문에서 정의하는 zero-shot learning은 학습과정에서 한번도 보지 못한 문제 및 데이터셋에 대해서 그 성능을 평가하는 것이다. 예를 들어 학습된 CLIP 모델을 이용해서 ImageNet 데이터의 분류 과정을 수행하는 것이다. 평가 대상이 되는 데이터셋이 다르며, 이미지-텍스트 연결이 아닌 이미지 분류 문제에 적용하는 것이므로 문제의 타입 또한 다른 상황이다.
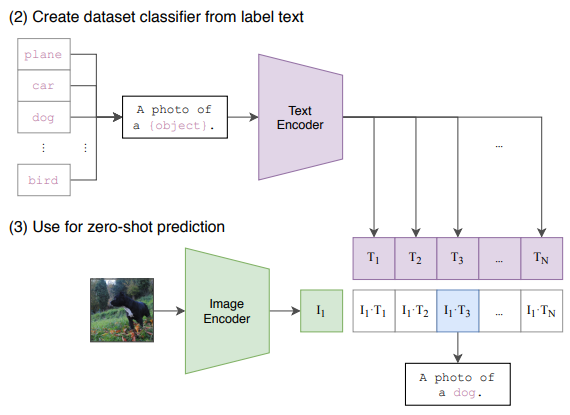
분류 문제를 위해 위의 그림과 같은 방법으로 CLIP 모델을 적용하였다. 이미지가 주어졌을 때 학습된 이미지 인코더로 이미지 특징을 추출하고, 모든 class label (e.g., 개, 고양이, 바나나 등)을 텍스트 인코더에 통과시켜 텍스트 특징을 추출한다.
N개의 텍스트 특징들 중 이미지 특징과 가장 높은 상관관계를 가지는 텍스트를 입력 이미지의 물체 분류 결과로 선택하여 출력한다. 이런 과정을 수행했을 때 ImageNet에 대한 zero-shot learning 결과는 무려 76.2%로 매우 높은 성능을 보였다.
</aside>
<aside> ⚠️ KoCLIP 모델 구조
ViT + KoBERT (or any other Korean encoder LM)

ViT(Vision Transformer) ViT(Vision Transformer)는 이미지 인식을 위한 인공 지능 모델로, Transformer 알고리즘을 사용한다. Transformer 알고리즘은 자연어 처리 분야에서 가장 성능이 좋은 인공 지능 모델 중 하나로, 순차적인 정보를 처리할 수 있는 장점이 있다. ViT는 이미지를 입력으로 받고, 이미지의 각 픽셀을 개별 요소로 취급한다. 이렇게 취급한 픽셀을 기반으로 Transformer 알고리즘을 적용해서 이미지를 인식한다.
이러한 장점 때문에, ViT는 이미지 인식 작업 이외에도 적용할 수 있는 영역이 다양하다. 예를 들어, ViT는 이미지 캡션 생성, 이미지 검색, 이미지 음성 생성 등과 같은 이미지 인식과 관련된 작업에 적용할 수 있다. ViT는 이미지 인식 작업에만 국한되지 않고, 자연어 처리와 관련된 작업에도 적용할 수 있다.
KoBERT (or any other Korean encoder Language Model) KoBERT는 인공 지능 모델로, 자연어 처리를 위한 BERT(Bidirectional Encoder Representations from Transformers) 알고리즘을 적용한 것이다. BERT 알고리즘은 자연어 처리 분야에서 성능이 우수한 인공 지능 모델 중 하나로, 자연어를 처리할 수 있는 장점이 있다. KoBERT는 한국어를 처리하기 위해서 BERT 알고리즘을 적용한 것이다. KoBERT는 한국어 자연어 처리 작업에 적용할 수 있다. 예를 들어, KoBERT는 자연어 이해, 자연어 생성, 자연어 번역, 감성 분석 등과 같은 자연어 처리 작업에 적용할 수 있다.
RoBERTa(Robustly Optimized BERT Approach) 자연어 처리를 위한 인공 지능 모델로, BERT(Bidirectional Encoder Representations from Transformers) 알고리즘을 기반으로 한다. BERT 알고리즘은 자연어 처리 분야에서 성능이 우수한 인공 지능 모델 중 하나로, 자연어를 처리할 수 있는 장점이 있다. RoBERTa는 BERT 알고리즘을 기반으로 하지만, BERT 알고리즘의 학습 방법과 학습 데이터에 대한 제약을 완화한 것이다. RoBERTa는 BERT 알고리즘의 성능을 더욱 개선한 것으로, 자연어 처리 작업에 적용할 수 있다.
</aside>
<aside> 🌐 Multilingual
현재 Multilingual을 지원하는 M-CLIP 등의 오픈소스가 등장하였지만, KoCLIP 또한 간단한 영어 쿼리에도 작동을 하여, 다른 오픈소스와의 성능 비교 실험이 필요하다.
KoCLIP는 한국어 데이터 세트에서만 훈련되었지만, 간단한 단어(예: "dog", "car")에도 영어 쿼리가 놀라울 정도로 잘 작동한다는 것을 발견했다. 한국어로만 미세 조정된 모델이 ViT와 잘 작동하는 시맨틱 임베딩을 생성하는 데 성공했다는 것이 흥미롭다.
이는 다음의 두 가지 이유 중 하나일 수도 있고 이들의 조합일 수도 있다.
1. VIT Pretraining koclip-base, openai/clip-vit-base-patch32의 ViT 백본은 이미 영어 데이터 세트에서 사전 훈련되었다. 따라서, 그것의 임베딩은 여전히 영어 텍스트 임베딩으로 벡터 반수법을 수행할 수 있는 잠재 공간에 있을 가능성이 있다. 이 가설에 반대하는 한 가지 이유는 koclip-large가 유사한 다국어 동작을 보여주기 때문이다.
2. LM Knowledge Bleed klue/roberta-large는 자체 감독 방식으로 많은 한국어 텍스트 코퍼스에 대해 훈련되었다. 특히 현대 회화 한국어에서 영어 단어 번역의 빈도가 높은 것을 고려할 때, 영어 단어가 말뭉치의 일부에 포함되었다고 합리적으로 의심할 수 있다. 이것은 또한 영어 쿼리가 koclip-base와 koclip-large 모두에서 작동하는 이유를 설명할 수 있다. 이 가설에 반대하는 한 가지 이유는 KLUE의 저자들이 그들의 논문에서 텍스트 선택에 대한 한 가지 기준이 "코퍼스는 동시대 한국어로 작성되어야 한다"고 명시적으로 진술하기 때문이다.
</aside>
<aside> ⚠️ 기타 개념 정리
Zero-Shot Transfer Zero-Shot Transfer란, 인공 지능 모델이 새로운 상황에서 작동할 수 있도록 학습된 것을 의미한다. 일반적으로 인공 지능 모델을 학습시키기 위해서는, 그 모델이 처리할 수 있는 상황을 정의한 데이터셋이 필요하다. 이러한 데이터셋을 이용해서 인공 지능 모델이 정의된 상황을 이해하고 처리할 수 있도록 학습된다. 그러나 Zero-Shot Transfer는 인공 지능 모델이 정의되지 않은 상황에서도 작동할 수 있도록 학습한다. Zero-Shot Transfer는 인공 지능 모델의 일반화 성능을 개선시키기 위해 사용된다.
</aside>
<aside> 💡 ChatGPT가 설명하는 CLIP
CLIP(Contrastive Language-Image Pre-training)은 인공 지능 모델을 통해 이미지와 텍스트 정보를 연결하고 이해할 수 있는 능력을 갖춘 시스템이기 때문에, 이미지 캡션 생성과 같은 자연어 처리 작업에도 적용할 수 있다. 이미지와 텍스트 정보가 주어졌을 때 이를 이해할 수 있는 인공 지능 모델을 구축할 수 있다.
</aside>
<aside> 💡 ChatGPT가 설명하는 KoCLIP
한국어 데이터셋으로 학습한 CLIP 모델
KoCLIP(Korean Corpus for Language Informatics and Processing)는 한국어 자연어 처리에 사용되는 코퍼스입니다. 코퍼스는 언어 처리 작업에 사용되는 데이터 집합을 의미합니다.
KoCLIP은 일반적인 코퍼스와는 차이점이 있는데, 이는 기존 코퍼스들과는 달리 자연어 처리에 필요한 데이터가 전문적으로 수집되어 정제된 것이라는 점입니다. 이는 KoCLIP을 이용한 자연어 처리 작업의 정확도를 높일 수 있는 장점을 제공합니다.
KoCLIP은 자연어 처리에 필요한 다양한 종류의 데이터를 제공하는데, 이는 언어 모델(language model) 구축, 감정 분석(sentiment analysis), 자연어 생성(natural language generation) 등 자연어 처리 작업에 사용될 수 있습니다.
KoCLIP은 국립국어원에서 제공하고 있으며, 자연어 처리 작업에 필요한 여러가지 종류의 데이터를 제공합니다. 이는 언어 모델 구축, 감정 분석, 자연어 생성 등 자연어 처리 작업에 사용될 수 있습니다.
KoCLIP은 여러가지 종류의 데이터를 제공하는데, 이는 일반 코퍼스, 상품 코퍼스, 영화 리뷰 코퍼스, 소설 코퍼스, 신문기사 코퍼스 등 여러가지 종류가 있습니다. 이들 코퍼스들은 자연어 처리 작업에 각각 적합한 데이터입니다.
KoCLIP을 이용한 자연어 처리 작업은 여러가지 장점을 제공합니다.
첫째, KoCLIP은 자연어 처리에 필요한 데이터가 전문적으로 수집되어 정제된 것이라는 점입니다. 이는 KoCLIP을 이용한 자연어 처리 작업의 정확도를 높일 수 있는 장점을 제공합니다.
둘째, KoCLIP은 여러가지 종류의 데이터를 제공하기 때문에, 자연어 처리 작업의 종류에 따라 적절한 코퍼스를 선택할 수 있습니다. 이는 자연어 처리 작업의 정확도를 높일 수 있는 장점을 제공합니다.
셋째, KoCLIP은 자연어 처리 작업을 수행할 때 일반적인 코퍼스들과는 달리 한국어 전문적인 코퍼스이기 때문에, 한국어 자연어 처리 작업에 적합한 데이터를 제공합니다.
</aside>
<aside> 🛠 ChatGPT가 설명하는 KoCLIP 학습방법
KoCLIP 모델을 학습하려면, 우선 이미지와 한국어 텍스트 쌍이 있는 데이터셋이 필요합니다.
이미지와 한국어 텍스트 쌍이 있는 데이터셋은 인터넷에서 찾아볼 수 있거나, 직접 수집할 수 있습니다. 이미지와 한국어 텍스트 쌍이 있는 데이터셋을 준비한 후, KoCLIP 모델을 학습시키기 위해서는 일반적인 인공 지능 모델 학습과 같은 절차를 따릅니다.
우선, KoCLIP 모델을 정의하고, 이미지와 한국어 텍스트 쌍이 있는 데이터셋을 이용해서 KoCLIP 모델을 학습시킵니다. 이때, 학습 알고리즘과 학습 속도, 학습 시간 등을 조절할 수 있습니다.
이미지 캡션 생성은 이미지를 입력으로 받아서 이미지에 대한 설명을 자동으로 생성하는 작업입니다. 이미지 캡션 생성을 위해서는 이미 학습된 KoCLIP 모델을 이용해서 이미지를 입력으로 넣고, 출력으로 생성된 이미지 캡션을 읽고 이해할 수 있습니다.
이미지 캡션 생성 외에도, KoCLIP 모델을 이용해서 이미지 설명과 같은 자연어 처리 작업을 수행할 수 있습니다.
</aside>